Pix2Pix 실습
Gan이기 떄문에 학습 시간이 오래걸림. 반드시 GPU로 하길바람

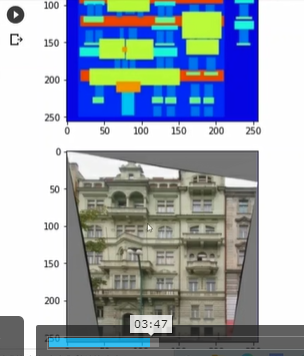
input이 추상적인 이미지이고 Ground Truth도 같이 넣어서 pix2pix로 만드는 것을 목표로 함.



그리고 데이터셋을 이 URL에서 가져옴. 이 파일을 얻은 다음에 path를 잡음


이미지를 로드하는 함수를 만듬. 이미지를 로드해서 읽어오고 jpeg은 영상이기 때문에 이미지로 decoder를 한다.
그런데 이 shape가 있는데 w= width를 나타내고,
w//2를 해서 real_image와 input_image에 넣는 이유는 이 image안에는 input Image와 Ground Truth 이미지가 같이 붙어 있음. 그래서 따로 떨어지게 해서 변수에 할당해준다.
이제, 정수형 타입인데 계산을 하다보면 실수가 생기기에 실수형 타입으로 형변환해줌.

하나 정도 읽어오자. 결과

input과 real 이미지를 resize해줌

random_crop함수는 위의 real_image처럼 테두리를 임의로 잘라서 여러개의 이미지로 만들고 싶을 때.
(데이터가 부족할 때, 더많은 데이터를 만들때 사용함)

-1 ~ 1까지로 정규화를 해준다.

random_jitter함수는 약간씩 옆으로 resize 해준 다음, 256x256으로 랜덤하게 잘라 여러개를 만들고, 랜덤한 확률로 좌우 뒤집기를 해주는 함수
(여러개의 이미지를 만들 때 사용)


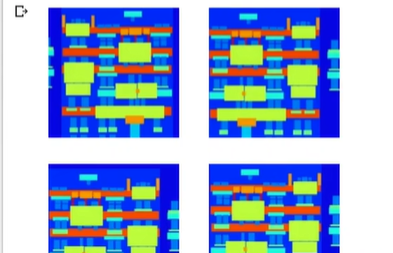
random_jitter함수를 한번 해보면 잘려진 부분이 다르고 좌우 반전이 되어있고... 비슷해보이지만 다 다른 이미지를 생성



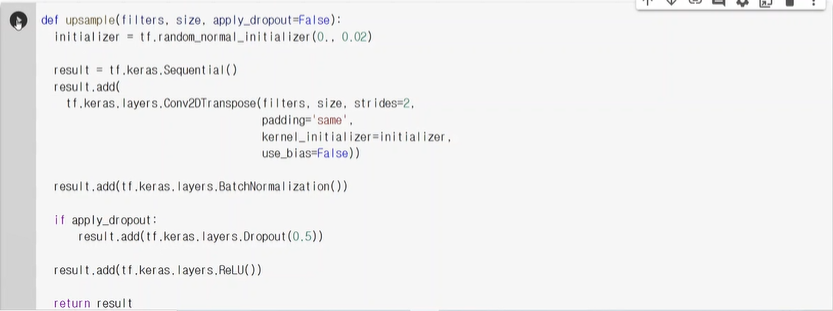
Generator를 만들어서 output채널은 3개로

downsample을 하는데 3x3필터로 strides =2를 함으로써 반으로 줄여주고 batchnormal적용.

이 모델을 통과하면 (1,128,128,3)으로 반 줄어든 것을 볼 수 있음
보통 다운샘플은 encode부분에서 사용한다.
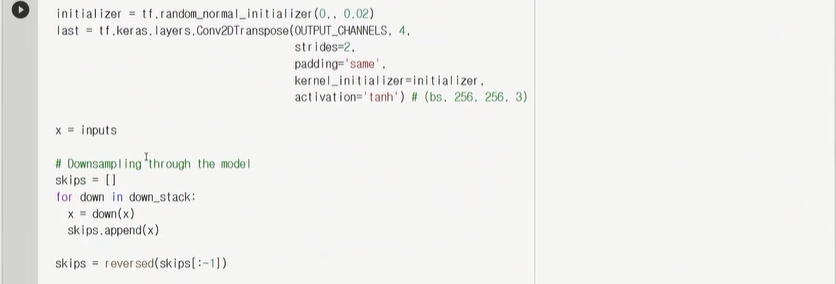
upsample을 씀으로써 사이즈를 늘려줌( 여기서 Conv2DTranspose함수를 쓰는 것을 볼 수 있음)

확인용으로 돌려보면 (1,256,256,3)으로 아까 줄였던 사이즈를 원래 사이즈로 돌아온 것을 볼 수 있다.



skips이라는 것은 작아졌다가 기냥 커지면 인코더, 디코더이기 때문에,
skip connection이 생기도록 중간의 output들을 skips배열에 모아놓음.
(가로x세로x채널) 원래 256x256x3이 최종으론 256x256x3가 나올 것이다.
for문 안에선 하나씩 커지는데, up_sstack과 skips끼리 Concatenate()한다.-(사이즈맞게 짝을 맞춰)
그렇게 해서 마지막에 나오는 x가 되고, 리턴으로 이런 함수를 맏는다.

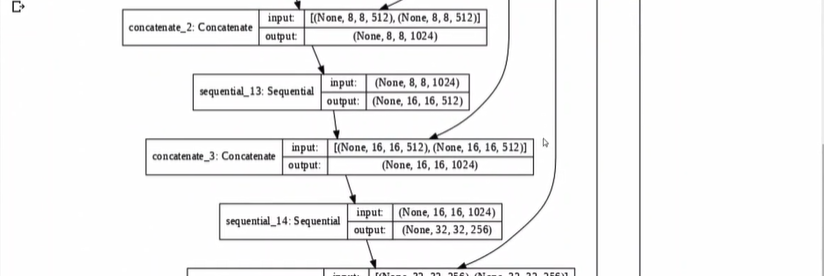
중간중간 위에서 내려온 것들이 skip connection임을 알자.


아직 학습이 안되서 진짜 영상처럼 안보임.(초기의 결과지)

generator loss를 만들자!

tf.ones_like()와 disc_generated_output간의 loss를 gan_loss라 지정해줌.
또한 l1_loss를 줘서 아웃풋으로 나온 것과 target과의 너무 차이가 생기지 않도록 한번 더 loss를 더줌
이 두개를 합친 것을 total loss로 둔다.
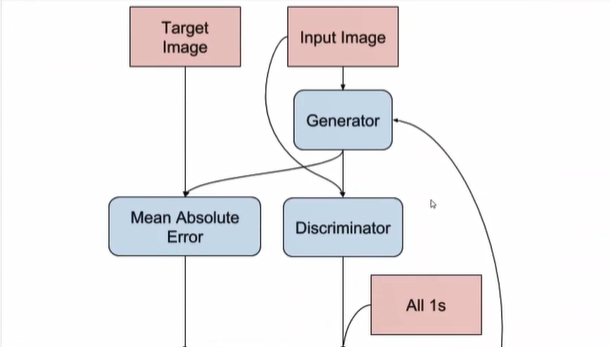



이제 Discriminator를 만들자.



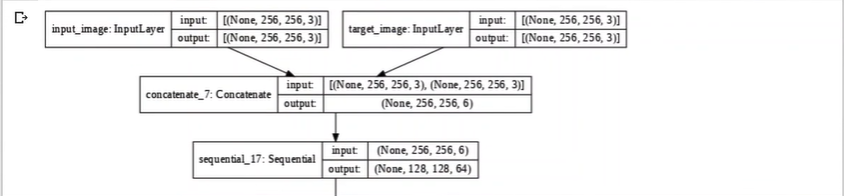

마지막으론 30x30x1이 나온다.


Discriminator를 한번 써봤지만 의미없는 값이 나온다. - 아직 학습을 안시켜서 그럼~
원래 우리가 원하는 결과는 가짜라면 전부다 0이고 진짜면 모든 위치에서 1이 나와야함.



real_loss에선 1이 나오길 바라고, generated_loss에선 0이 나오길 바라니깐 tf.ones_like(), tf.zeros_like()함수를 쓴 것을 볼 수 있음. 두개의 loss를 합친 것이 total_disc_loss가 됨.

그리고 optimizer들을 설정해줌.
중간에 weight값을 저장하는 checkpoint를 지정해줌.


generate_images()함수는 모델을 가져다가 prediction을 보여주기 위해 만든 함수임
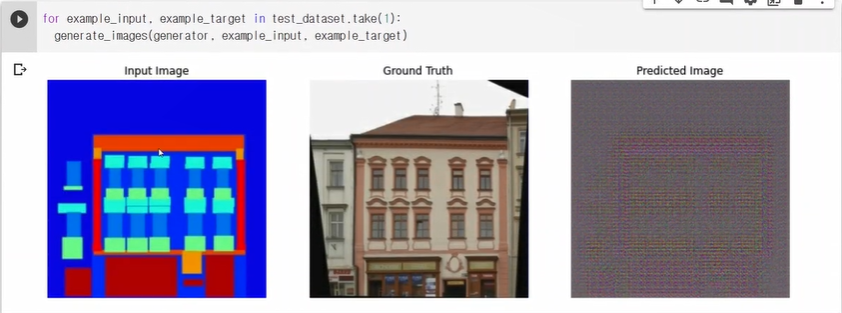
위의 함수를 써보기 위한 코드 -아직 학습이 되지 않았기에 predict이미지가 의미가 없음




DCGan에서 본것처럼 gradient를 저장하는 tape를 만들었음.
자 이제 train함수를 만들었고 이 함수를 여러번 수행하는 함수를 만들자.

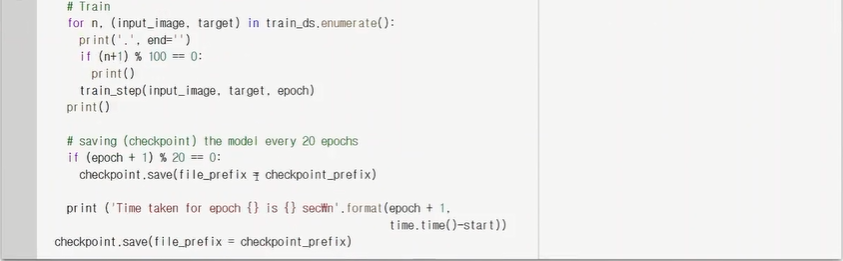



여기서 fit()함수를 호출해서 learning을 하게 된다.
나머지는 test데이터에 대해 어떻게 하는지에 대한 코드이다.
Cycle Gan 실습
cycle Gan은 Pix2Pix를 기반으로 만들었음.

말 영상을 입력으로 받으면 얼룩말 형태로 변환시켜줌.

필요한 코드를 clone하고

tensorflow_datasets를 사용함.
pix2pix에서 모듈을 가져올 것임. (pix2pix에선 직접 만들어봤지만 이번엔 제공된 generator랑 discriminator를 쓴다.)


dataset를 load함. dataset은 trainA, trainB, testA, testB로 되어 있고. A는 말 영상, B는 얼룩말 영상이 있음


Pix2pix에서 했던 crop함수도 만들어주고 normalize함수도 생성


jitter 함수도 정의함.

train 데이터는 random_jitter 실행 후 정규화 실행 후 image를 리턴함.

test 데이터는 jitter로 이미지량을 늘릴 필요없으므로 normalize만 진행한다.

map함수를 써서 아까 만든 함수를 모든 이미지에 적용시킨다.(shuffle도 적용)
train, test 모두 진행.( 둘 다 다른 함수로 진행하는 것 잊지 말기)

train_horses에서 하나(sample)를 가져옴.
가져와서 어떻게 생겼나 볼까?
sample_horse 리스트는 (1,256,256,3)으로 되어 있는데 뒤에 [0]을 붙이는 이유는 이 앞의 1을 없애주기 위해서.
그러면 크기와 채널만 남으니깐
그 것을 보여주고,jittering을 해봄.



거의 유사한 영상이 하나 더 만들어진 것을 볼 수 있음.

얼룩말에 대한 영상도 한번 보자


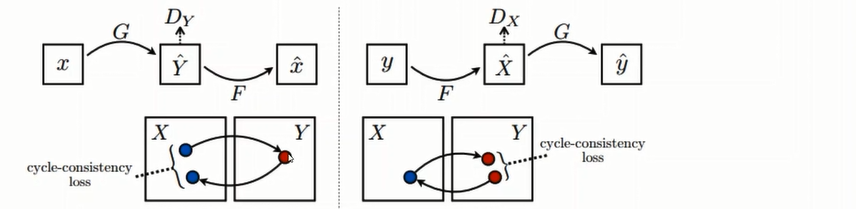
G는 말을 얼룩말을 바꾸는 함수.
F는 얼룩말을 말로 바꾸는 함수.
Dx(discriminator_x)는 진짜 x(말영상)랑 generated_x(얼룩마로부터 만들어진 영상) 를 구분함
Dy(discriminator_y)는 진짜 y(얼룩말 영상)랑 generated_y(말로부터 만들어진 얼룩말 영상)를 구분함

generator는 pix2pix라는 모듈의 unet_generator를 호출해서 만듬.
discriminator도 pix2pix 모듈안의 discriminator 함수ㅡㄹ 호출해서 만들었음.

to_zebra은 sample 데이터로 zebra 영상을 만들었음(대신 학습이 되어 있지 않아, 제대로 만들어지지 않을 것임.)
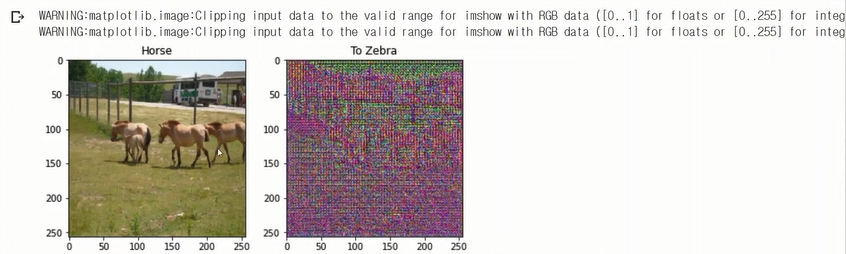
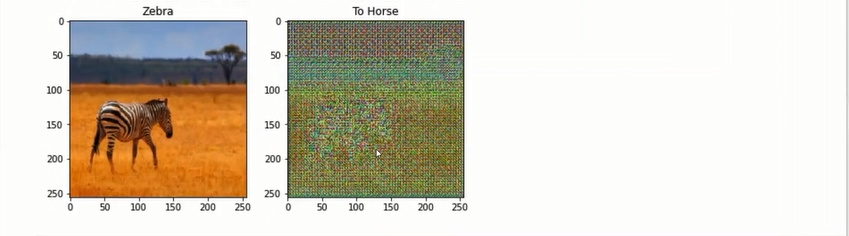

discriminator도 학습이 되어있지 않기 때문에 제대로 판별을 못해줌.
진짜 zebra는 32x32의 출력이 전부 1이 나와야했는데, 아니면 0이 나와야함.(아직 제대로 학습이 되지 않아서)
자 이제 Loss Func 보자.



discriminator_loss에선
진짜에 대해선 1이 되었으면 좋겠고 generated에선 0이 되었으면 좋겠으니 그런 loss를 만들고 그것을 합침.

generator_loss에선
generated가 1과 가까워 지기를 원하므로.
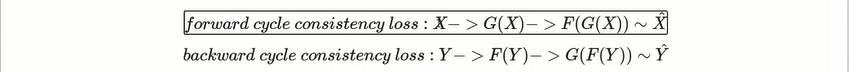
cycle gan에선
X에 대해서 말->얼룩말->말 로 갔을 때 이 말과 말의 차이가 최소화가1 되기를 원함. =X_hat
Y에 대해서 얼룩말 -> 말 -> 얼룩말 로 이 차이를 최소화가 되기를 . Y_hat

한 사이클 돌아온 이미지를 cycled_image라 지정한다.
그거의 절대값의 평균을 최소화하는 loss를 만듬.

cycle loss 만으로도 안정하게 하길 원하지만,
얼룩말(Y)이 말로 바뀌어도(G(Y)) 원래 자기랑 너무 차이가 크지 않게 만들도록 하는 identity loss
(완전히 똑같으면 안되지. 완전히 똑같으면 얼룩말이 얼룩말이 되는 것이니깐. 어느정도만 차이가 있겠끔)


optimizer들을 설정해준다.


check point를 설정해준다.


학습을 시작하기 위한 준비.
generate_image 함수는 학습된 결과를 보여주기 위한 함수

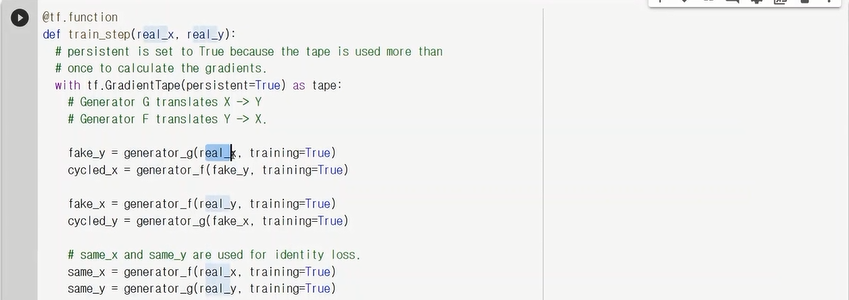
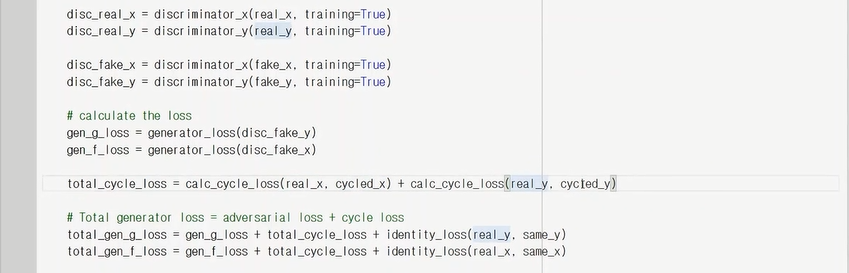


fake_y는 genrator_g함수로 말을 얼룩말로 만들어주고,
cycled_x는 generator_f함수로 얼룩말로 만들었던 fake_y를 다시 말로 만들어주었다.
calc_cycle_loss로 real_x와 cycled_x의 차이를 값으로 구해서 더한 후 total_cycle_loss에 넣어준다.
total_cycle_loss를 total+gen_g/f_loss의 일부분으로 넣었고, identity_loss(말(real_loss)과 그 말로 변형한 얼룩말(same_loss)의 차이 loss도 추가했음. 또한 gen_g_loss에는 discriminator로 가짜 영상을 판별하여 generator_loss함수에 넣었음.
이것들을 다합쳐서 total_gen_g_loss가 된다.(말을 얼룩말로 바꿀때의 loss)
total_gen_f_loss(얼룩말을 말로 바꿀때의 loss)
loss를 구해주면 gradient값을 구한다!
다음으로 최적화를 실행해준다.(optimizer)
이렇게 train_step함수를 정의한다.


epoch을 넣어서 train_step함수를 수행한다.
한 에폭 자체가 상당히 오래 걸림....

시간이 지나서 10epoch정도 지났음. 30epoch까지 갈려면 멀었지만, 얼룩말의 무늬가 점점 보여지는 ㄱ서을 볼 수 있다.

train이 끝나고 난뒤 test 데이터의 결과를 볼 수 있음.

'AI > vision' 카테고리의 다른 글
| GAN - Pix2Pix, ConditionalGAN, CycleGAN (0) | 2021.08.10 |
|---|---|
| DCGAN 실습 (0) | 2021.08.09 |
| Image Segmentation 실습 (0) | 2021.08.09 |
| MaskRCNN, custom MaskRCNN (0) | 2021.08.09 |
| Pose and Face Estimation (0) | 2021.08.09 |


댓글