지난번 옥스포드 pets영상을 사용하기로 함.




지난 번 6개 라인(헤더)은 제거하고 나머지에 대해서 라인을 읽음


image_file은 원본영상이고, mask_file은 segmantic된 영상이 있는 파일이다.


데이터셋은 numpy로 바꿔준 다음에

split을 한 후 리턴해줌.
load_oxford_pets_2()란 함수를 정의를 했음.

x_train과 x_test는 기존 데이터셋에 0~1사이의 값으로 normalize해서 넣어준다.
y_train에선 1: 배경 2:object 3:boundry 픽셀을 -1로 해서 0,1,2로 해줌
train dataset은 5880개, test dataset은 1469개
상이즈는 128x128 채널은 RGB 3개의 채널
y_train은 채널이 한개짜리 라벨 마스크



3개의 채널을 갖는 128x128 이미지가 들어가고, 구분할 num_classes는 3개이다.(배경, 객체, boundry)
down은 계속 사이즈가 작아지는(downsampling) layer를 뜻한다.
center는 여기서는 사이즈를 바꾸진 않지만 conv를 두번정도 수행해줌
up은 upsampling이 일어남.
- concatenate함수가 down1과 up1를 합치는 부분(손실된 정보를 채우는 부분)
- upSampling을 먼저 수행후 같은 사이즈를 만들어 놓고 concatenate함수를 수행

1x1 conv를 수행해서 하나의 채널이 나오게 함. (채널은 클래스별로 나옴)



이제 fit함수를 써서 학습을 시키면..




#7에서 test 데이터에 대해 pred_mask를 만든 후
display함수를 써서 원래 영상과 y_test(ground truth)와 pred_mask를 비교한다)
epoch를 현재는 3인데 3은 너무 적고 최소 20은 해야함.

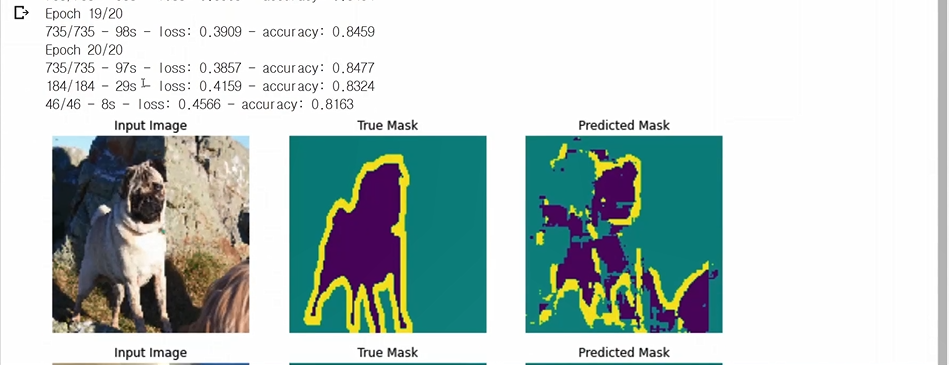
아주 간단한 UNet이라 결과가 좋진 않음..
이번엔 Unet 구조를 조금 더 깊게 만들어 보자.


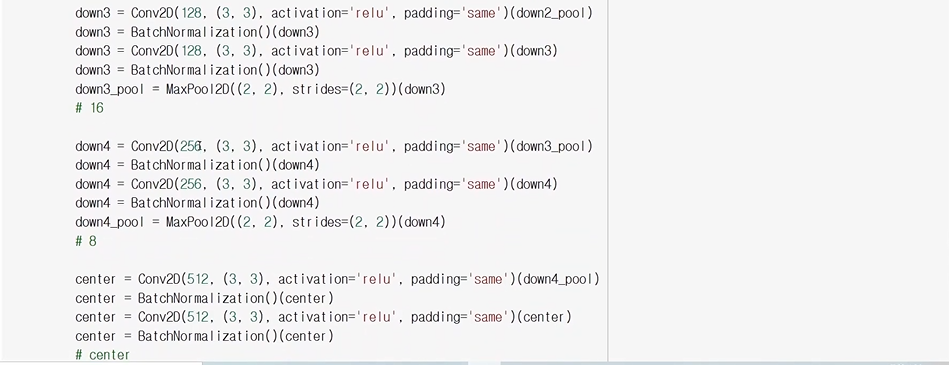






모델의 구조가 많이 복잡해짐을 볼 수 있다.
이제 아까 학습시키는 코드를 사용하여 학습을 시켜 결과를 보게 되면.

predicted Mask가 true Mask와 많이 가까워진 것을 확인할 수 있다.
'AI > vision' 카테고리의 다른 글
| GAN - Pix2Pix, ConditionalGAN, CycleGAN (0) | 2021.08.10 |
|---|---|
| DCGAN 실습 (0) | 2021.08.09 |
| MaskRCNN, custom MaskRCNN (0) | 2021.08.09 |
| Pose and Face Estimation (0) | 2021.08.09 |
| Semantic Segmentation - FCN/PSPNet (0) | 2021.08.09 |

댓글