
tensorflow.org 밑에 tutorials 세션이 있음. 다양한 분야의 인공지능을 만들어 놓음.
처음 시작은 tensorflow.org에서 배우는게 좋은 생각이 듬.
Run in colab을 클릭하면 colab으로 열리고 이 코드를 드라이브에 사본 저장하면 됨.
처음 부분은 GAN이 무엇인지...
mnist dataset처럼 숫자들을 생성하는 코드임




우리는 필요한게 train에 대해서만 필요함.
train_image를 4차원으로 바꿔줌.
늘 convolution 함수에 들어가게 되면 4차원이여야 함(영상의 갯수, height, width, 채널)
타입을 실수로 변경하고 normalize 진행

생성자(Generator)를 만드는 함수.




Conv2DTranspose함수는 진행할수록 영상사이즈가 더 커진다.
128, (5,5) strides=(1,1)을 둠으로써 영상 사이즈는 그대로 두고 채널의 갯수를 128로 줄인다.
그 이후 strides=(2,2)로 두어 사이즈를 반으로 늘린다. 14x14x64 또한 채널의 수도 64로 줄여줌.
한번더 strides를 2배로 하여 28x28x1로 만든다. 영상사이즈 28x28에 채널 1개


noise를 generator에 통과시켜 결과를 보자.
아직 학습을 하지 않았기에 아무 의미 없는 결과가 나옴.


Conv2D라 사이즈의 크기는 작아짐.
input은 28x28x1이고 아웃풋은 conv결과를 flatten해서 real인지 fake인지를 구분해줌.

이 결과론 0.0011로 아무 의미없는 값이 나옴. Discriminator도 아직 학습이 되어 있지 않다.

BInaryCrossEntropy를 loss함수로 설정하겠다. from_logits를 True로 주면 one-hot encoding으로 나옴
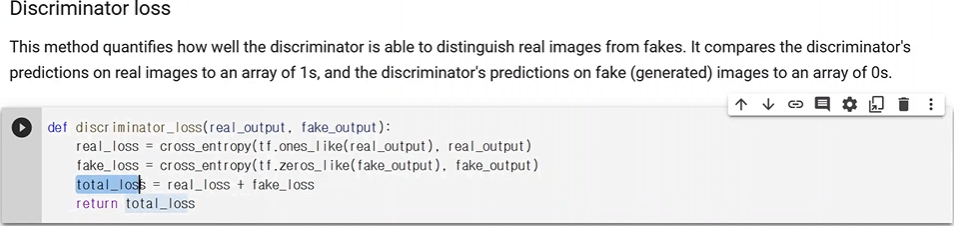
real_loss와 fake_loss의 합


G(z)는 가짜 영상.

Generator는 Dicriminator를 속이고 싶기 때문에,
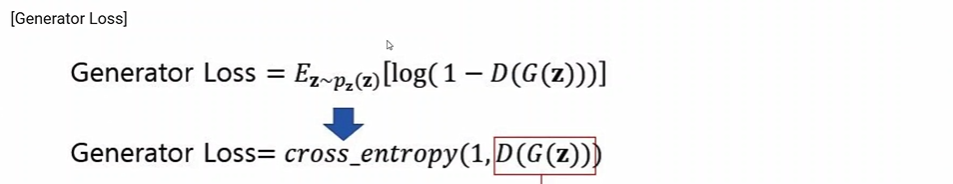


optimizer 가 2개 필요함.
generator와 discriminator 각각의 학습이 필요하기 때문

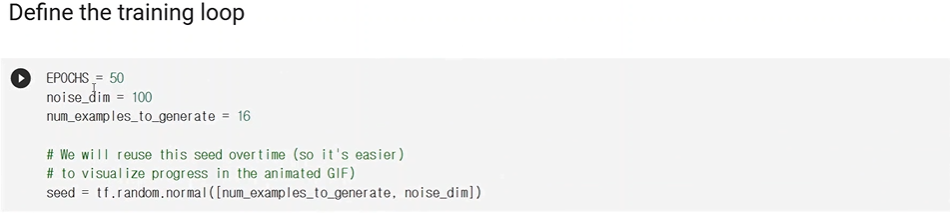
노이즈의 크기는 100
생성하고자하는 영상은 16개이다.

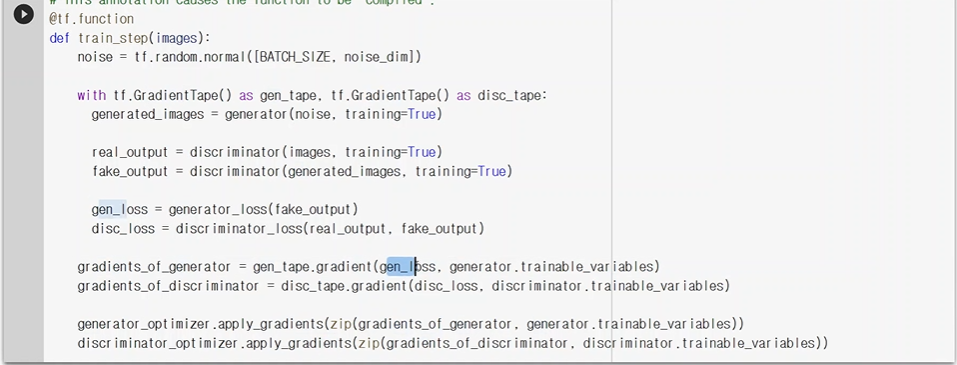
tf.GradientTape() 는 generator와 Discriminator를 위해 tape 두개를 만듬.
tape는 순차적으로 기록이 되는 함수. - 무엇을 기억하냐면 forward를 하면
그 아웃풋값들을 저장을 함. backpropgation을 할때 weight값을 계산할 수 있게 도와줌
real_output에는 진짜 이미지를 discriminator모델을 거친 아웃풋을 넣고,
fake_output에는 generator가 만든 이미지를 discriminator모델에 넣어 나온 아웃풋을 넣는다.
두 loss를 둘 다 최소한으로 만드는 방향으로 갈려한다.
gen_tape에는 loss(gen_loss)에 weight(generator.trainable_variables)에 대한 gradient값을 기록해놓음
이것을 gradients_of_generator에 저장한다.
discriminator도 똑같이 해줌.
apply_gradients를 통해 weight(~~~.trainable_variabels)에 gradient를 적용시킴. -> 가중치를 업데이트 시킨다.
이부분이 train_step이란 함수이다.


batch마다 train_step을 불러 모델을 학습 시키고,
15 epoch마다 checkpoint를 저장한다.

모델에다가 test image를 넣어서 예측값을 뽑아냄.
train함수를 불러 학습을 시작한다.


'AI > vision' 카테고리의 다른 글
| Pix2Pix, CycleGan 실습 (2) | 2021.08.14 |
|---|---|
| GAN - Pix2Pix, ConditionalGAN, CycleGAN (0) | 2021.08.10 |
| Image Segmentation 실습 (0) | 2021.08.09 |
| MaskRCNN, custom MaskRCNN (0) | 2021.08.09 |
| Pose and Face Estimation (0) | 2021.08.09 |


댓글