* 이 공부노트는 프로그래머스 인공지능 데브코스 주차 과제를 바탕으로 제작되었습니다.
- 음식배달 서비스를 위한 예측 모델을 만들기. 즉 음식 배달에 걸리는 시간을 예측하는 모델을 만드는 것이다.
- kaggle의 Predicting Food Delivery Time 데이터셋 안에 있고, 실제로 이걸 우리가 직접 만들어보았다.(물론 따라하면서....)
- 여기서 예측된 배달시간이 실제 배달시간보다 더 걸리는 경우 리스크는 두배가 됨을 가정으로 한다. ( 예로 카카오 택시 앱을 보면 도착까지 드는 예상 금액이 실제 금액보다 높은 경우가 있는데, 이와 같은 원리로 적용된다고 보면 된다. 예상금액보다 더 들면 솔직히 기분 나쁘니깐 - 기술적인 요인 말고 인적인 요인이 첨가된 것일 뿐)
우선 데이터를 보면
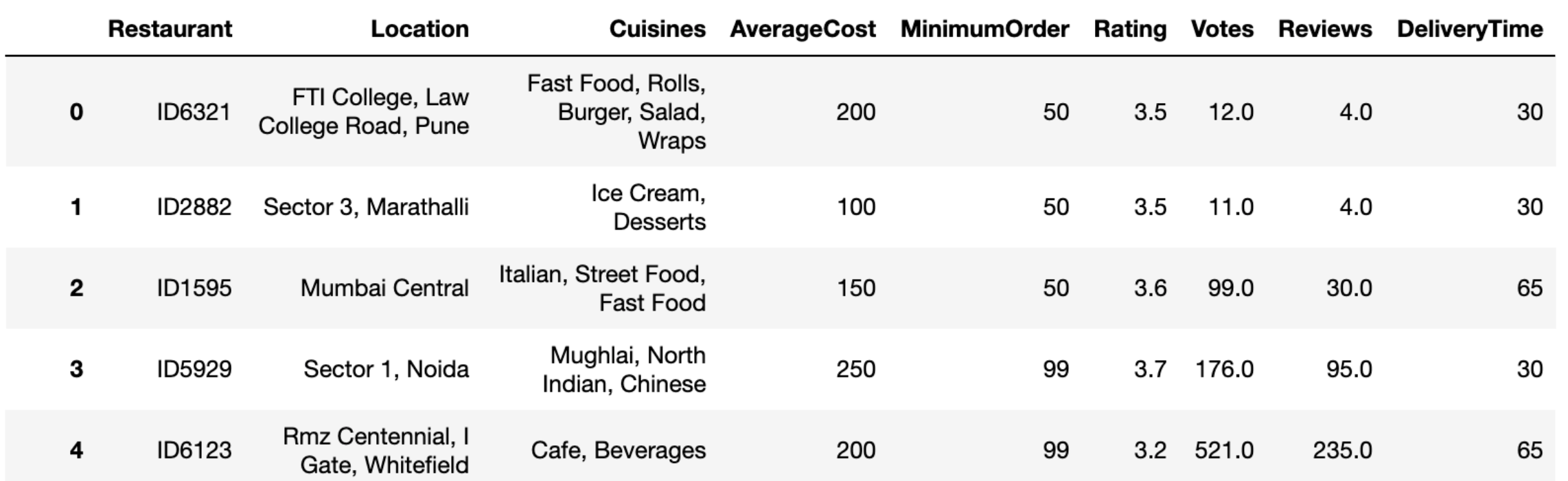
Restaurant, Location, Cuisines, AverageCost, MinimumOrder, Rating, Votes, Reviews 의 컬럼이 있다. 이 열들을 이용하여(변수의 형변환, 범주형 변수를 더미변수로 만든다던가 등)을 해서 DeliveryTime을 예측하는 것이다.
- Restaurant : 레스토랑 고유 ID
- Location : 레스토랑 위치
- Cuisines : 레스토랑에서 제공하는 요리
- Average_Cost : 1인 주문에 대한 평균 비용
- Minimum_Order : 최소 주문 금액
- Rating : 레스토랑에 대한 고객 평가
- Votes : 고객 투표 수
- Reviews : 고객 리뷰 수
- Delivery_Time : 배달 시간 (Target Classes)
delivery_df.info()의 결과는
<class 'pandas.core.frame.DataFrame'> RangeIndex: 11094 entries, 0 to 11093 Data columns (total 9 columns): Restaurant 11094 non-null object
Location 11094 non-null object
Cuisines 11094 non-null object
AverageCost 11094 non-null object
MinimumOrder 11094 non-null int64
Rating 9903 non-null object
Votes 9020 non-null float64
Reviews 8782 non-null float64
DeliveryTime 11094 non-null int64
dtypes: float64(2), int64(2), object(5) memory usage: 780.1+ KB
여기서 Restaurant , Location , Cuisines 말고는 다 숫자형인데 AverageCost ,Rating 이 객체형으로 반환된 것을 볼 수 있다. 이것은 나중에 int형이나 float형으로 고쳐 사용한다.
다음으로 변수들을 그래프로 표현해봤다.
%matplotlib inline
import matplotlib.pyplot as plt
delivery_df.hist(bins=50, figsize=(20,15))
plt.show()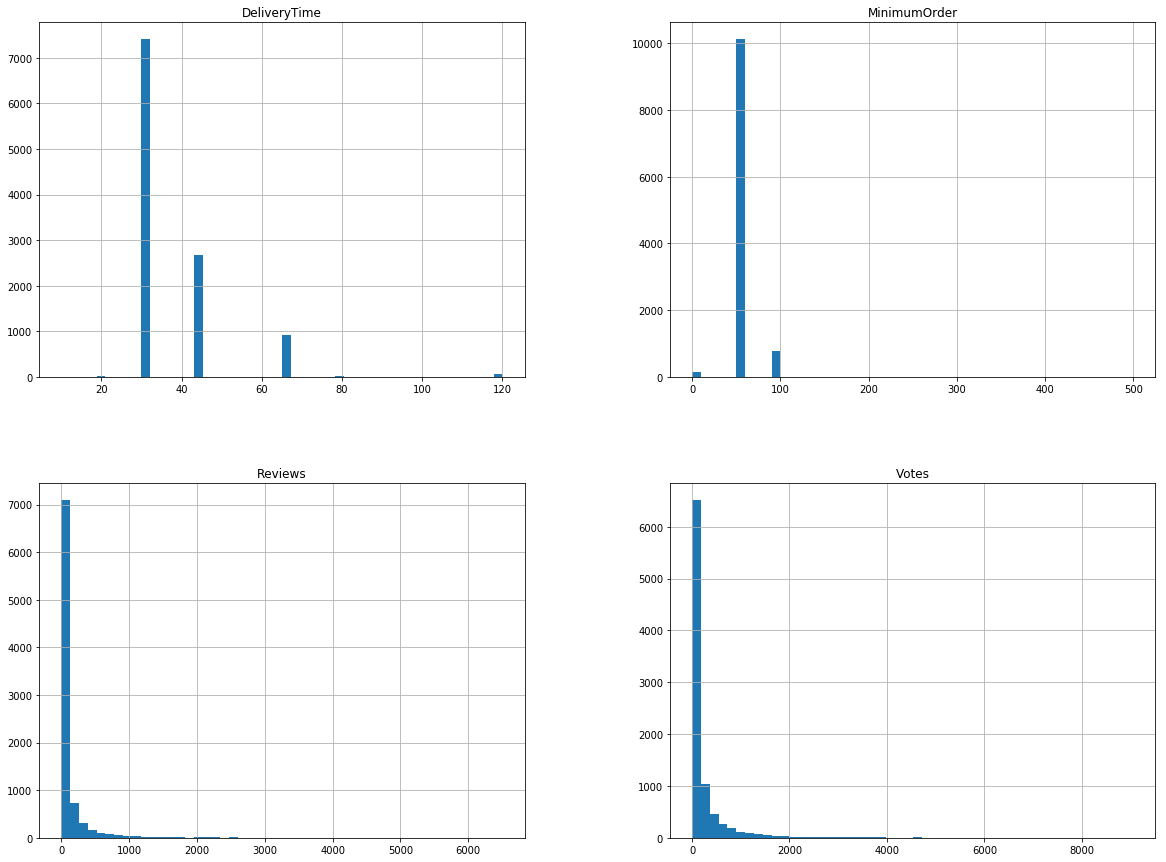
DeliveryTime : 이산적인 느낌의 그래프 - 30분, 45분 등등 나뉜 걸로 봐 엄청나게 세세하게는 표현되지는 않은 듯하다.
MinimumOrder : 이산적인 느낌의 그래프. - 0과 50, 100의 느낌이 강하네. $가 기준이면 55000원이상으로 시켜야 배달되는 곳도 있다. 이것은 kaggle 데이터상 설명에서도 자세하게 나와있지 않아 그냥 예측일 뿐이다.(하지만 미국이니깐 이해되는 느낌)
Reviews, Votes : 확실히 이것은 0에 제일 가까운 수가 많은 현실적인 데이터와 비슷하다.
다음으로,
train, test 데이터 나누기
train_set과 test_set을 나눴다. kaggle에 들어가보면 train과 data가 나눠진 것을 볼 수 있지만, 이번 과제로 받은 똑같은 데이터는 train+test로 주셨기에 임의로 나눴다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(delivery_df, test_size=0.2, random_state=42)
#len(train_set), len(test_set)실제 sklearn에선 데이터를 나눠주는 모듈이 있다. 이걸 쓰면 매우 편하게 나눠진다.
test_size : 테스트 데이터셋의 비율.
random_state : 데이터가 나눠질 때, 셔플이 이루어지는데 이를 위한 시드값. 이 값을 고정적으로 사용하면 매번 데이터셋이 변경되는 것을 막을 수 있다.
delivery_df = train_set.drop("DeliveryTime", axis=1) # drop labels for training set
delivery_labels = train_set["DeliveryTime"].copy()
test_delivery_df = test_set.drop("DeliveryTime", axis=1)
test_delivery_labels = test_set["DeliveryTime"].copy()데이터셋에서 예측의 결과값이 되는 DeliveryTime을 따로 빼뒀다.
데이터 전처리 (범주형 변수 변환, null값 변환, object값 숫자형 변환)
scikit-learn을 이용해 범주형 데이터를 쉽게 수치형 데이터로 바꿀 수 있다.
0과 1로 이루어진 다수의 열을 만드는 one-hot encoder와 달리 label encoder는 하나의 열에 서로 다른 숫자를 입력해준다.
from sklearn.preprocessing import LabelEncoder
#le.fit_transform :
le=LabelEncoder()
delivery_df['Restaurant']=le.fit_transform(delivery_df['Restaurant'])
delivery_df['Location']=le.fit_transform(delivery_df['Location'])
문자형으로 들어온 AverageCost, Rating을 변환한다.
column 내 문자인 것은 형변환 시 NaN으로 대체한 후 median값을 채워 넣는다.
delivery_df['AverageCost']=pd.to_numeric(delivery_df['AverageCost'],errors='coerce')
delivery_df['Rating']=pd.to_numeric(delivery_df['Rating'],errors='coerce')
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
delivery_num = delivery_df.drop(['Cuisines'], axis=1)
imputer.fit(delivery_num)
X = imputer.transform(delivery_num)
#imputer.statistics_
delivery_tr = pd.DataFrame(X, columns=delivery_num.columns,index=delivery_df.index)pd.to_numeric()함수를 써서 object형을 int형이나, float형으로 바꿔 줄 수 있다.
이 함수의 파라미터에서 errors='coerace'는 만약 숫자가 아닌 문자가 있는 행인 경우 NaN값을 반환한다는 소리이다.
즉 예로 ['4', '6', '5', '3', 'for', '1']이란 리스트가 있으면 여기서 for만 NaN으로 반환하고 나머진 숫자값으로 변환해준다.[4, 6, 5, 3, NaN, 1]
다음에 SimpleImputer로 NaN값을 그 열의 Median값으로 변환한다.
imputer가 적용될 때, df에 Object가 있는 열이 있으면 오류를 발생할 수 있기에 여기서 유일하게 Object인 Cuisines 만 버리고 조정을 한다.
결과적으로,
사실 이 모든 과정을 PipeLine을 쓰면 한번에 해결이 가능하다.
이렇게 데이터를 전처리하고 정규화를 시켜 ML 모델을 만드는데, 이 전처리+정규화를 한번에 도와주는 것이 PipeLine이라 보면 된다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
#저번 시간에 pipeline 한 번 해봤지>?? 여러개의 변환이 순차적으로 진행할 때 굉장히 편함
#3가지 작업을 할려고 함.
# 1. SimpleImputer 사용해서 missing value에 median값을 넣어주려 함.
# 2. 우리가 만들었던 CombinedAttributesAdder한 transformer를 할려함.
# 3. feature값을 평균이 0 분산이 1이 되도록 만들어주려함.
#Pipeline([('임의의 이름',추정기),('임의의 이름',변환기),()])
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('std_scaler', StandardScaler()),
])
delivery_prepared = num_pipeline.fit_transform(delivery_num)마지막 fit_transform으로 변환시켜주면 Data를 ML 모델에 넣을 준비가 끝난 것이다.
모델 만들기
이제 모델을 만들건데, 나는 우선 LinearRegression(선형회귀), LogisticRegression(비선형 회귀), RandomForest(비선형회귀) 로 3가지 모델을 만들어봤다.
사실 선형회귀보단 비선형회귀가 더 잘 나올 것이라 생각된다. 지금 변수들이 거의다 연속형이 아니고 이산형이면서 0 or 1이란 느낌의 변수들이 많다.(물론 Binary하지는 않는다.) 그래서 비선형회귀가 더 높은 정확도를 나오지 않을까 하고 해본 것이다. (초보라 이런 추측만 할 뿐..... 처음 해보는거니 우선 해보자)
LinearRegression
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(delivery_prepared, delivery_labels)
scores = cross_val_score(lin_reg, delivery_prepared,delivery_labels, cv=10) # model, train, target, cross validation
print('cross-val-score \n{}'.format(scores))
print('cross-val-score.mean \n{:.3f}'.format(scores.mean()))
결과 :
cross-val-score
[0.11098881 0.10257772 0.15198226 0.14188712 0.10485654 0.17711045 0.08953501 0.08044242 0.1015975 0.08066096]
cross-val-score.mean 0.114
MAE(Mean Absolute Error)
from sklearn.metrics import mean_absolute_error
delivery_predictions = lin_reg.predict(delivery_prepared)
lin_mae = mean_absolute_error(delivery_labels, delivery_predictions)
lin_mae결과 :
8.437247756953496
test_set MAE, Accuracy
delivery_predictions = lin_reg.predict(test_delivery_prepared)
lin_mae = mean_absolute_error(test_delivery_labels, delivery_predictions)
print('MAE :',lin_mae)
pred = lin_reg.predict(test_delivery_prepared)
print("Test Accuracy: {}%".format(round(lin_reg.score(test_delivery_prepared, test_delivery_labels)*100, 2)))결과 :
MAE : 8.289362438679829
Test Accuracy: 8.4%
정확도가 8.4%.... 말이 안나온다.ㅎ
LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
model_lr = LogisticRegression()
model_lr.fit(delivery_prepared, delivery_labels)
scores = cross_val_score(model_lr, delivery_prepared,delivery_labels, cv=10) # model, train, target, cross validation
print('cross-val-score \n{}'.format(scores))
print('cross-val-score.mean \n{:.3f}'.format(scores.mean()))결과 :
cross-val-score
[0.69481982 0.70157658 0.70608108 0.6981982 0.6981982 0.68207441 0.69785795 0.67869222 0.6854566 0.69222097]
cross-val-score.mean 0.694(다양한 경고들이 엄청 나왔다;;;)
MAE(Mean Absolute Error)
from sklearn.metrics import mean_absolute_error
delivery_predictions = model_lr.predict(delivery_prepared)
log_mae = mean_absolute_error(delivery_labels, delivery_predictions)
log_mae결과 :
6.304225352112676
test_set MAE, Accuracy
delivery_predictions = model_lr.predict(test_delivery_prepared)
log_mae = mean_absolute_error(test_delivery_labels, delivery_predictions)
print('MAE:',log_mae)
print("Test Accuracy: {}%".format(round(model_lr.score(test_delivery_prepared, test_delivery_labels)*100, 2)))결과 :
MAE: 5.9711581793600725
Test Accuracy: 70.71%
RandomForest
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(delivery_prepared, delivery_labels)
scores = cross_val_score(rf, delivery_prepared,delivery_labels, cv=10)
print('cross-val-score \n{}'.format(scores))
print('cross-val-score.mean \n{:.3f}'.format(scores.mean()))결과 :
cross-val-score
[0.79279279 0.77702703 0.78378378 0.77927928 0.78490991 0.7621195 0.789177 0.75310034 0.77339346 0.77113867]
cross-val-score.mean 0.777
RandomForest-MAE(Mean Absolute Error)
from sklearn.metrics import mean_absolute_error
delivery_predictions = rf.predict(delivery_prepared)
forest_mae = mean_absolute_error(delivery_labels, delivery_predictions)
forest_mae결과 :
0.0016901408450704226
test_set MAE, Accuracy
delivery_predictions = rf.predict(test_delivery_prepared)
forest_mae = mean_absolute_error(test_delivery_labels, delivery_predictions)
print('MAE:',forest_mae)
print("Test Accuracy: {}%".format(round(rf.score(test_delivery_prepared, test_delivery_labels)*100, 2)))결과 :
MAE: 5.128436232537179
Test Accuracy: 74.9%
최종적으로 RandomForest가 제일 높은 정확도(74.9%)를 보였다.
이렇게 최초로 Kaggle을 데이터셋을 가지고 가공하고 ML 모델을 만들어 보았다...
하지만 아직 부족한게 너무 많다.
기존 예상 배달 시간이 넘는 리스크를 2배로 여기는 것도 아직 적용하지 않았고, RandomForest의 모델 튜닝도 해보진 않았다. 더하여 다른 모델들 SVM, PCA가 여기에 적용할 수 있는지도 해보지 않았기에, 공부해야할 건 더 늘어났다.ㅜ
우선은 여기까지 리포팅을 하고 더 추가되는 것은 추후 넣을 예정이다.(so hard...)
'ML > ML-Kaggle, 데이콘' 카테고리의 다른 글
| 랜덤포레스트(RandomForestRegressor) (3) | 2021.09.29 |
|---|---|
| 결측값 전처리 (0) | 2021.09.29 |
| 의사결정나무 (0) | 2021.09.28 |
| 당뇨병성 망막병 검출(Diabetic Retinopathy Detection) (0) | 2021.08.11 |
| kaggle에서 colab으로 데이터 가져오기 (0) | 2021.08.11 |


댓글