앙상블 기법 - 배깅, 부스팅, 랜덤포레스트 등의 기법 중 랜덤포레스트에 대해 알아보자.
랜덤포레스트는 의사결정나무를 여러개를 모아다 합쳐놓은 것이다.
일종의 배깅인데, 각 의사결정나무에 여러개의 샘플 데이터를 추출하여 추론한 후 회귀이면 의사결정나무들의 결과의 평균을 구하고, 분류이면 투표를 통해 최종적으로 값을 구한다.
각 의사결정나무들은 기존 데이터에서 랜덤하게 표본을 추출하고 각자 독립적으로 계산한다.
랜덤포레스트 모듈의 옵션 중에 criterion옵션을 통해 어떤 평가지표를 기준으로 훈련할 것인지 정할 수 있다.
평가 지표 중엔 회귀에 RMSE, MAPE 등이 있고 분류엔 Confusion Matrix정도가 있다.
여기서 RMSE를 인자로 써본다. (보통 RMSE =MSE를 제일 많이 쓰긴 한다)

# 데이터 다운로드 링크로 데이터를 코랩에 불러옵니다.
!wget 'https://bit.ly/3gLj0Q6'
import zipfile
with zipfile.ZipFile('3gLj0Q6', 'r') as existing_zip:
existing_zip.extractall('data')
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
train=pd.read_csv('data/train.csv')
test=pd.read_csv('data/test.csv')
#결측치 확인
print(train.shape)
print(train.head(10)
print(train.info())
print(train.isnull().sum())
#결측치 전처리. 시계열 데이터이므로 보간법으로 실행
train.interpolate(inplace=True)
test.fillna(0, inplace=True)
# X_train, Y_train으로 분류
X_train=train.drop('count', axis=1)
Y_train=train['count']
#모델을 불러와서 훈련시키기
model=RandomForestRegressor(criterion='mse')
model.fit(X_train, Y_train)
fit() 으로 모델이 학습되고 나면 feature_importances_ 속성(attribute) 으로 변수의 중요도를 파악 가능하다.
변수의 중요도란 예측변수를 결정할 때 각 피쳐가 얼마나 중요한 역할을 하는지에 대한 척도이다.
변수의 중요도가 낮다면 해당 피쳐를 제거하는 것이 모델의 성능을 높일 수 있음.
# 랜덤포레스트모델 예측변수의 중요도를 출력
model.feature_importances_
이제 필요없는 변수들을 제거해보자.

X_train df를 보면 사실상 예측에 상관없는 변수가 있다.
예로 id같은 경우 예측엔 전혀 필요없는 변수이기에 제거해주는 것이 낫다.
또한 데이콘에서 hour_bef_windspeed와 hour_vef_pm2.5 피쳐도 제거해보는 것을 추천했다.
# X_train 에서 drop 할 피쳐의 경우에 수 대로 3개의 X_train 을 생성
# 각 train 에 따라 동일하게 피쳐를 drop 한 test 셋들을 생성
X_train1=train.drop(['count','id'],axis=1)
X_train2=train.drop(['count','id','hour_bef_windspeed'], axis=1)
X_train3=train.drop(['count','id','hour_bef_windspeed','hour_bef_pm2.5'],axis=1)
test1=test.drop('id',axis=1)
test2=test.drop(['id','hour_bef_windspeed'],axis=1)
test3=test.drop(['id','hour_bef_windspeed','hour_bef_pm2.5'],axis=1)
# 각 X_train에 대해 모델 훈련
model_input_val1=RandomForestRegressor(criterion='mse')
model_input_val1.fit(X_train1,Y_train)
model_input_val2=RandomForestRegressor(criterion='mse')
model_input_val2.fit(X_train2,Y_train)
model_input_val3=RandomForestRegressor(criterion='mse')
model_input_val3.fit(X_train3,Y_train)
# 각 모델로 test 셋들을 예측
pred_test1 = model_input_val1.predict(test1)
pred_test2 = model_input_val2.predict(test2)
pred_test3 = model_input_val3.predict(test3)
# 각 결과들을 submission 파일로 저장
submission_1 = pd.read_csv('data/submission.csv')
submission_2 = pd.read_csv('data/submission.csv')
submission_3 = pd.read_csv('data/submission.csv')
submission_1['count'] = pred_test1
submission_2['count'] = pred_test2
submission_3['count'] = pred_test3
submission_1.to_csv('sub_1.csv',index=False)
submission_2.to_csv('sub_2.csv',index=False)
submission_3.to_csv('sub_3.csv',index=False)
하이퍼파라미터 튜닝은 정지규칙을 설정한다는 의미라고 한다. (정지규칙은 접은 글을 보자)
즉 의사결정나무의 모델의 인자를 설정해서 과적합을 방지한다.
의사결정나무에는 정지규칙(stopping criteria)란 개념이 존재하는데, 정지 규칙이 없다면 학습데이터를 완벽하게 학습하게 되다보면 어느샌가 과적합이 발생해 테스트 데이터에는 성능이 낮게 나온다. 그렇기 때문에 어느 정도 선에서 끊어 주는 것이 필요한데 이것을 정지규칙이라 한다.
의사결정나무의 하이퍼 파라미터(인자)로는 아래와 같이 설정이 가능하다.
- 최대깊이(max_depth)

최대로 내려갈 수 있는 depth 입니다. 뿌리 노드로부터 내려갈 수 있는 깊이를 지정하며 작을수록 트리는 작아지게 됩니다. - 최소 노드 크기(min_sample_split)
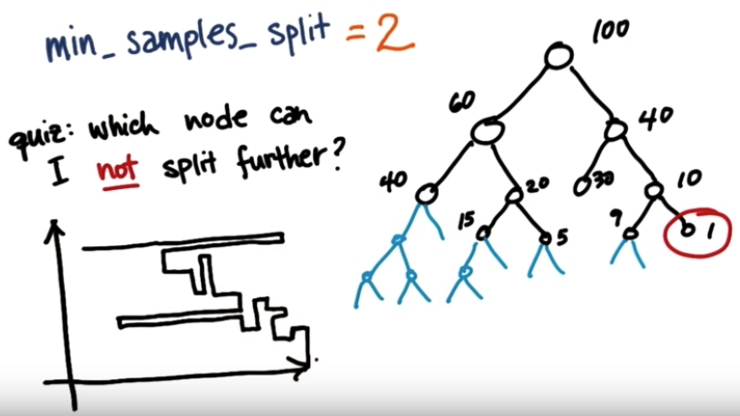
노드를 분할하기 위한 데이터 수 입니다. 해당 노드에 이 값보다 적은 확률변수 수가 있다면 stop. 작을수록 트리는 커지게 됩니다. - 최소향상도(min_impurity_decrease)
- 노드를 분할하기 위한 최소 향상도 입니다. 향상도가 설정값 이하라면 더 이상 분할하지 않습니다. 작을수록 트리는 커집니다. - 비용복잡도(Cost-complexity)

- |T|: 최종노드의 개수
- 𝛼: 패널티 계수 (트리가 커지는 것에 대한 패널티를 사용자가 정함)
- 각 𝛼 값마다, 가장 Cost 를 적게 하는 트리 T 가 존재함
- 𝛼=0 이라면, 최대크기의 트리가 가장 선호됨 (0.5 면 뿌리노드)

𝛼 값이 작으면 train 데이터에 대해서는 정확도가 높지만, test 데이터에 대해서는 정확도가 낮을 수 밖에 없습니다. 모든 𝛼 값을 비교해보면 최적의 𝛼 값을 관찰할 수 있습니다. 이러한 최적의 𝛼 값은 교차타당성(Cross-Validation) 을 통해 찾을 수 있습니다. 뒤에서 이에 대해 다루도록 하겠습니다.
출처 : https://github.com/pyohamen/Im-Being-Data-Scientist/wiki/Hyperparameters-tuning
하이퍼파라미터 튜닝에는 다양한 방법론이 있다고 한다.
그 중 Best 성능을 나타내는 GridSearch는 완전 탐색(Exhaustive Search) 을 사용.
가능한 모든 조합 중에서 가장 우수한 조합을 찾아주지만, 완전 탐색이기 때문에 Best 조합을 찾을 때까지 시간이 매우 오래 걸린다는 단점이 생긴다.
from sklearn.model_selection import GridSearchCV
# params를 설정해줘야한다.
# 여기서 dict 형태로 랜덤포레스트의 하이퍼 파라미터의 변수명을 정확히 써줘야 에러를 방지할 수 있다.
# 왜냐면 GridSearchCV로 model인 랜덤포레스트를 설정한 하이퍼파라미터 대로 돌려보는 거니깐!
params={'n_estimators':[200,300,500],
'max_features':[5,6,8],
'min_samples_leaf':[1,3,5]}
# GridSearchCV 모델을 설정해준 후 랜덤포레스트 모델과 랜덤포레스트의 하이퍼 파라미터인 params를 넣어준 다음
# GridSearchCV의 모델 인자들을 넣어준다.
greed_CV=GridSearchCV(model, param_grid=params, cv=3, n_jobs=-1)
#모델을 학습시킨다.
greed_CV.fit(X_train3, Y_train)
# test데이터로 예측값을 출력해보자.
pred = greed_CV.predict(test3)
# 이제 예측한 값을 csv파일로 저장해보자.
# 기존 공백의 submission.csv파일을 불러온 후 넣어줘서 다운받는다.
submission=pd.read_csv('data/submission.csv')
# 예측한 값이 소숫점 자리가 너무 길어서 두자리까지만 끊어서 넣어준다.
import numpy as np
submission['count']=np.round(pred,2)
# 저장!
submission.to_csv('sub.csv',index=False)
랜덤포레스트 하이퍼 파라미터 설명:
[Chapter 4. 분류] 랜덤포레스트(Random Forest)
4-3. Random Forest In [1]: from IPython.core.display import display, HTML display(HTML(" ")) 1. 배깅(Bagging)이란?¶ 배깅(Bagging)은 Bootstrap Aggregating의 약자로, 보팅(Voting)과는..
injo.tistory.com
GridSearchCV 설명 :
https://rudolf-2434.tistory.com/10
머신러닝 GridSearchCV 로 하이퍼 파라미터 학습과 최적화
GridSearchCV 란? 사이킷런에서는 분류 알고리즘이나 회귀 알고리즘에 사용되는 하이퍼파라미터를 순차적으로 입력해 학습을 하고 측정을 하면서 가장 좋은 파라미터를 알려준다. GridSearchCV가 없다
rudolf-2434.tistory.com
'ML > ML-Kaggle, 데이콘' 카테고리의 다른 글
| 수치형 데이터 정규화 (0) | 2021.10.08 |
|---|---|
| 이상치(Outlier) (0) | 2021.10.08 |
| 결측값 전처리 (0) | 2021.09.29 |
| 의사결정나무 (0) | 2021.09.28 |
| 당뇨병성 망막병 검출(Diabetic Retinopathy Detection) (0) | 2021.08.11 |


댓글