

darknet을 clone하기



80개의 클래스를 가진 데이터셋으로 사전 학습된 가중치들 다운로드함.


pc에서 구글 colab으로 업로드할때 쓰는 함수와
그 반대인 download 함수

darknet 폴더 안에 detect를 사용

클래스에 대한 정보를 가지고있는 cfg 파일 - yolov3.cfg
어떤 가중치를 불러서 detect할 것인가. - yolov3.weights
어떤 이미지를 분류할 것인지.
나온 결과는 predictions.jpg로 저장된다.

다른 사진에 대해서도 분류해보자.





CustomYolo v3 만들기

우리가 원하는 object에 대해 검출할 수 있는 모델을 만들자.









커스텀 데이터셋이 필요한데, 우리가 일일이 만들 수도 있고 데이터셋을 다운로드 해도 되고.
cfg file을 수정

Yolo ver에서 사용하는 라벨이 여기와는 조금 달라서 약간의 수정이 필요하다.
사이트를 들어가 보면 open Image dataset v6 이다. type을 detection으로 변경하면 박스가 되어 있는 객체를 볼 수 있음
이것을 다운로드 받을 수 있지만 영상과 라벨에 대해서 처리를 해줘야하고 약간 번거러움
이것을 쉽게 해주는 툴킷이 OIDv4 toolkit임.- 폴더를 영문명으로 해줘야함(경로에 한글이 나오면 오류발생)
github.com/theAICuysCode/OIDv4_Toolkit에서 git clone을 해야함.
local에서 git clone <클론된 주소> 로 다운을 받는다.
그 후에 OIDv4_Toolkit으로 들어가서
pip install -r requirements.txt로 라이브러리를 다운로드한다.(아나콘다에선 잘 안되서 하나하나 다운받음 conda 명령어로)


classes 이후에 우리가 원하는 클래스를 적으면 됨.
limit 300은 각 클래스마다 300개만 받겠다.
--multiclasses 1을 붙이지 않으면 각각 다른 폴더 안에 생성됨.
이것을 붙이면 모든 클래스가 하나의 폴더안에 다운된다.
폴더에 들어가보면 이미지와 label txt파일이 생성됨
label txt파일은 한 이미지 안에 어떤 객체가 있고 좌측 상단 x,y 우츠하단 x,y 좌표가 적어져있다.
그런데 yolo에서는 전체 영상을 0~1로 보기 때문에 이 좌표들을 normalize해야함.
(우리가 직접 짤 수 있지만 누군가가 만들어 놓은 코드가 있기 때문에 그것을 써보자)

yolo 포멧을 변환시켜줌. - 다시 가서 확인 해보면 아까 이미지 옆에 txt 파일이 생성되고 그 안에 좌표값이 0~1사이로 바뀐 것을 볼 수 있음. (예전 라벨은 yolo에서 필요없기 때문에 삭제해도 됨)
다시한번 정리해보자. 커스텀 데이터셋 마련을 위해
- 구글 open images dataset에 관심있는 클래스에 대해 이미지를 하나의 폴더 안에 다운 받고
- OIDv4_ToolKit의 root folder 폴더에서 classes.txt라는 파일을 열고 각 라인에 클래스명을 하나씩 적어놓는다.
- 그리고 convert_annotations.py을 실행해서 이 이미지에 해당하는 라벨 txt파일(yolo에 맞게)을 만들어줌


방법2는 직접하므로 굉장히 시간이 많이 걸림...
local에 다운받은 train 데이터셋을 colab에 올려야지.

클래스별 이름을 이어붙인 폴더명을 obj로 변경하고 압충하여 colab에업로드 한다.
!cp = copy를 뜻함. 앞에 경로의 파일을 ../ = 현재 경로에 복사한다.


압축을 풀기.

cfg파일을 수정해야함.
이 파일은 yolo를 어떻게 학습시킬지, 네트워크 구조를 간단하게 설명해놨음.
yolov3.cfg는 coco 데이터셋으로 학습이 된 파일.

cfg를 열어보면


testing은 이미지가 1개이므로 batch=1이되고.
지금은 학습해야 하기 떄문에 test부분의 batch를 주석처리하고, traing의 batch를 주석을 푼다.


학습을 위해 한번에 64개의 batch를 할 것이고, 이것을 16등분(subdivisions)해서 학습을 시킨다.
local에서 학습을 시킬때 메모리 부족시 subdivisions를 올리면 해결될 수 있음.
그다음에 바꿔야 되는게, max_batches =500200에서 -> 10000(max_batches는 최소 4000정도는 되어야함.)
steps 은 보통 max_batches의 80%, 90%에 해당되는 값을 넣어준다.
각각의 yolo layer의 클래스를 바꿔줘야함.
또한 filters=30으로 바꿔줌. 30이 나오는 이유는 (클래스의 갯수 + 5) * 3 = (클래스갯수+x,y,w,h,c)*anchor box 갯수
이런 yolo layer가 3개가 있으니, 이것도 다 위와 같이 수정해준다.




(반드시 순서가 맞게 써줘야함)

backup은 학습을 하다가 1000번에 한번씩 가중치를 저장하게 함.
두개의 파일을 만든 다음에.

data라는 폴더 안에다 넣어놓고,


학습에 사용하는 이미지의 경로를 갖다가 하나의 txt파일에 다 집어놓은 것.

colab에서 이 generate_train.py을 돌리면 train.txt파일이 생성되고 그 안에는 한줄마다 이미지의 경로가 적힌 것을 볼 수 있다.

function ClickConnect(){
console.log("Working");
document.querySelector("colab-toolbar-button#connect").click()
}
setInterval(ClickConnect,60000)
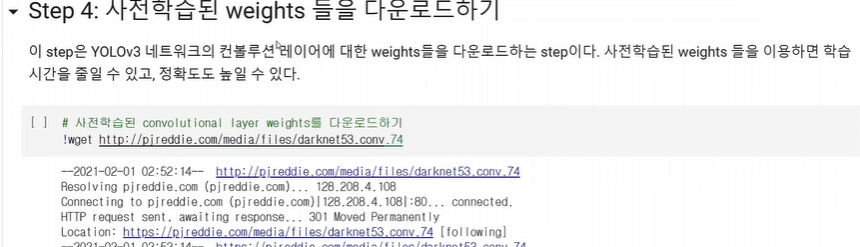
darknet53.conv.74는 초기의 가중치를 뜻함.(전이학습이므로)
학습을 하다 중간에 끊기면 저장해놨던 weight값을 darknet53.conv.74자리에 넣어주면 됨.

위의 코드로 training을 시작한다.(런타임을 gpu로 설정하길- 엄청오래걸림...14시간)


이 부분을 실행해야지 처음 darknet53.conv.74를 실행하면 처음부터 다시 시작하는 불상사가 발생하니 반드시 기억하길 바란다.

batch=64를 batch=1로 변환해주는 것.

우리의 라스트 weight와 test할 이미지 한개를 넣어주면 결과가 노은 것을 확인할 수 있다.

로컬에서 yolo webcam 실습
우선 로컬에서 돌려본 후 colab에서 돌려보자!



frame으로 부터 기본적인 blob= 출력결과로 얻은 값을 사각형을 씌워서 blob을 input으로 넣어서
forward를 해서 output을 내면




opencv는 기본적으로 cpu 버전임.
gpu에서 쓰고 싶다면 make를 해야함.
'AI > vision' 카테고리의 다른 글
| Pose and Face Estimation (0) | 2021.08.09 |
|---|---|
| Semantic Segmentation - FCN/PSPNet (0) | 2021.08.09 |
| Object Detection, OpenCV웹캠 실습 (0) | 2021.08.08 |
| SSD(Single Shot Detector) (0) | 2021.08.08 |
| Object localization, OpenCV 이미지 실습 (0) | 2021.08.06 |

댓글