이제 실습을 해보자.
Oxford Pet 데이터셋은 위의 url로 다운받을 수 있음.
(옥스포드에서 만든 데이터임. 개와 고양이를 모아놓은 데이터)
- Dataset
- Groundtruth data
두가지로 나뉜다.

아니면 한꺼번에 다운 받는 코드

images파일의 압축을 풀고

ls을 보면 images와 sample_data 파일이 있음을 알 수 있다.

이와 같이 annotations 파일의 압축을 풀면, annotations, images, sample_data파일이 있음을 볼 수 있다.


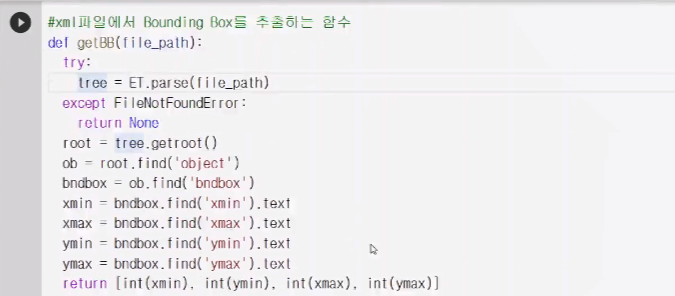
아까 위에 xml 파일을 가져와 tree 구조로 파싱을 한 후,

트리의 root부터 시작해서 object 가지를 찾아 ob변수에 넣고, bndbox를 찾고, xmin, xmax,ymin,ymax를 찾아서 변수안에 넣는다.


annotations밑의 list란 텍스트 파일을 읽는데,
list 파일로 부터 라인을 하나씩 읽어서 list_txt 변수에 넣은 후,
처음 6개의 라인은 제외시키고, list_txt를 적당히 섞는다.(shuffle)
train_dataset으로 이름, 라벨, 이미지, 박스 로 빈 리스트 생성
test_dataset도 똑같이 하되 박스만 없음.(박스는 정답에 해당하기 때문)
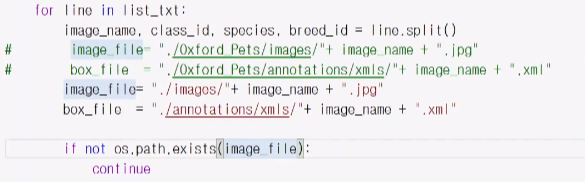
후에 line.split를 써서 list파일에서 받아온 것을 쪼개서 변수에 넣음.

img를 로드한 후 resize를 해줌.
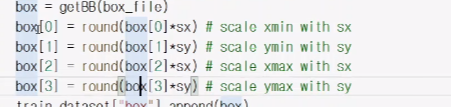
그러면 box의 좌표도 그에 맞게 바꿔줘야한다.(기존 box의 좌표는 원래 사이즈의 좌표이므로)
그리고 train_dataset 에 넣어준다.
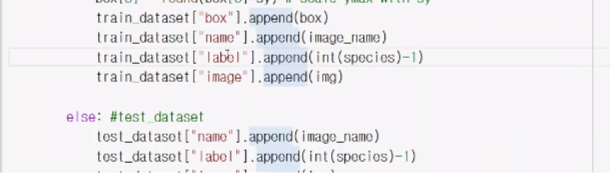
그리고 모두 np.array로 바꾼다음에 return 해준다.


위의 6줄은 어떤 헤더에 해당하고, 그 다음부터 파일명과 111
첫번째 1은 클래스 id, 두번째 1은 개와 고양이인지.(개는 1 고양이는 2)
세번째 1은 개의 종자(개의 종자는 12개 고양이의 종자는 25개로 나뉘어짐)
총 37개의 클래스가 있음을 알 수 있다.
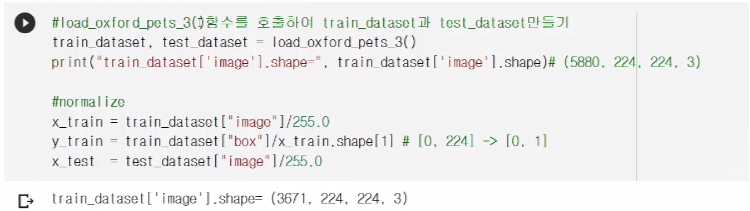
0~1사이로 normalize해준다. 박스도 0,224에서 0~1사이로 normalize한다.

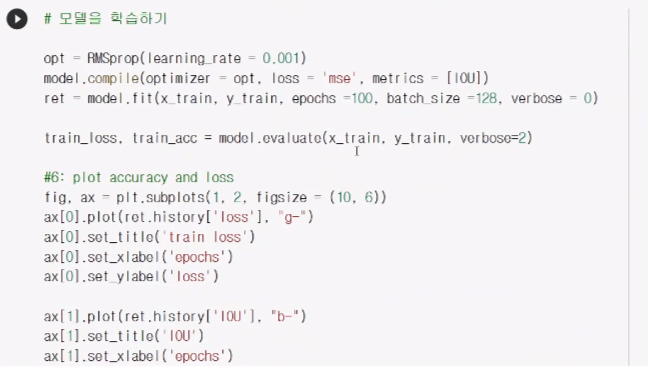
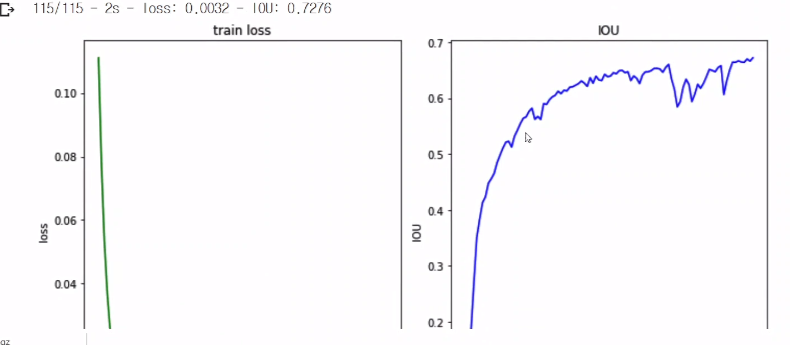
IoU함수를 만들어줌.(네트워크가 학습이 잘되엇다는 기준이 되어줌)
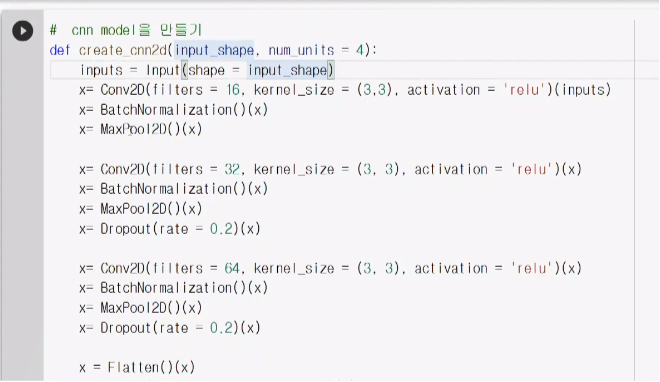

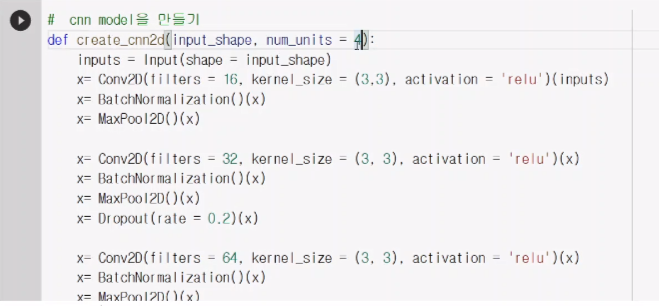
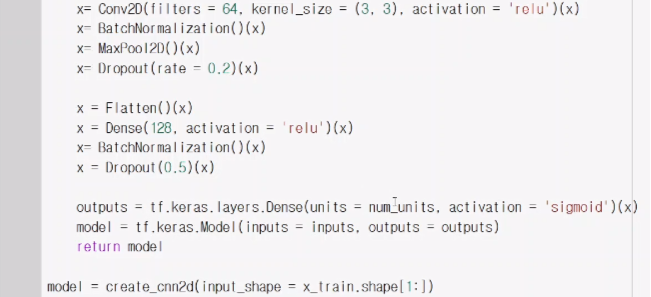
num_units =4인 이유는 우리가 뽑을려는 값이 4개이기 때문에 xmin,xmax,ymin,ymax

또다른 실습을 해보자.
mask RCNN에 앞서 openCV에 대한 간단한 실습을 해보자.
정지영상과 동영상을 어떻게 읽고 쓰는지에 대한 연습.
사진 파일을 업로드 한다.

파일을 한번 보자.

image 파일을 np.array로 변환 후 출력 r,g,b가 있는데 0번 채널이면 red
사진을 출력해보면 사람의 살색이 파랑색으로 스머프가 된 것을 확인할 수 있다.
gray 로 보여주는 예시

아까와 다르게 openCV로 파일을 불러왔을 땐 BGR형태로 불러온다.
원본 RGB가 BGR 형태로 넘파이 배열로 반환한다.(R과 B가 바뀜)
이처럼 R과 B가 바뀌어서 푸르스름해진 것을 볼 수 있다.


파랗던 얼굴이 다시 붉으스름한 정상적인 얼굴로 출력된다.
cvtColor(cv2_image, cv2.COLOR_BGR2RGB)를 씀으로써 바꿔진 것을 볼 수 있다.
openCV안에서 문제가 안되었던건 읽어올 때 BGR형태로 불러오지만 저장할 땐 다시 RGB형태로 변환하여 저장하기 때문.
그렇지만 딥러닝으로 처리하기 위해선 반드시 BGR을 RGB로 변환하는 것이 필요하다.
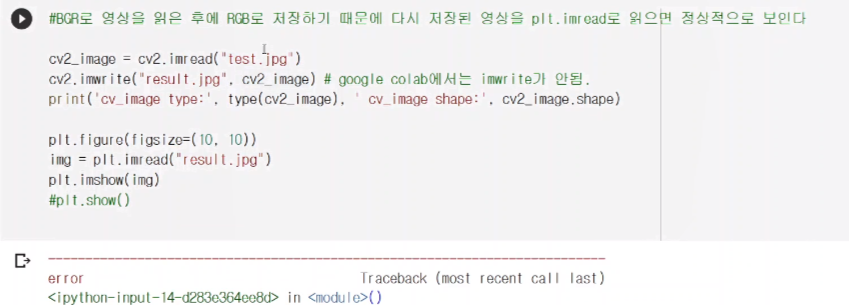
imwrite가 colab에서는 먹히지 않음.ㅜㅜ
local에서 실행한다면 다시 R과 B가 바뀐것이 원상복귀 되는 것을 볼 수 있다.

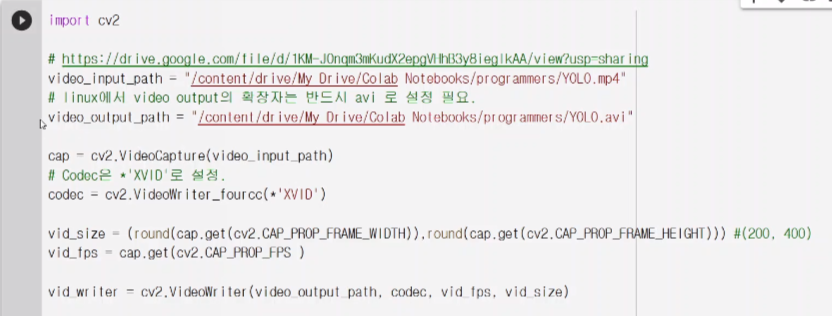
코덱을 xvid로 설정하면 avi로 저장됨.
cv2.VideoCapture()는 동영상을 한프레임씩 읽어내는 함수
cv2.CAP_PROP_FRAME_WIDTH/HEIGHT를 쓰면 가로,세로를 자동으로 계산해줌.
cv2.CAP_PROP_FPS는 초당 몇 프레임인지를 자동으로 계산해줌.
videoWriter를 할 때는 아웃풋 path와 코덱, fps, size 인자가 필요하다.'



while True:는 끝까지 읽겟다.
cap.read()는 hasFrame 과 img_frame을 반환해줌.
hasFrame은 boolean값으로 더 이상 처리할 frame이 없을 때 false 반환
cv2.rectangle하는 영상에다 사각형을 그려줌.
cv2.putText는 간단한 text를 써줌.
release()하면 파일이 처리됨.
'AI > vision' 카테고리의 다른 글
| Object Detection, OpenCV웹캠 실습 (0) | 2021.08.08 |
|---|---|
| SSD(Single Shot Detector) (0) | 2021.08.08 |
| Object Detection, Faster RCNN (0) | 2021.08.06 |
| Visual Recognition, 전이학습 (0) | 2021.08.06 |
| Yolo (0) | 2021.08.06 |

댓글