여러개의 모델을 결합하여 더 좋은 예측 결과를 도출하는 앙상블 기법이다.
간단하다. 다양한 모델의 결과들을 모아서 투표하는 것이다.
아주 간단한 예로 모델이 총 3개로 1번 모델, 2번 모델의 결과가 사과로 나왔다. 3번 모델의 결과는 배로 나왔으면 사과가 2표, 배가 1표이므로 이 것의 결과는 사과가 된다.
Voting Classifier 는 Hard voting과 soft voting으로 나뉘어진다.
Hard voting.
- Majority voting이라고도 하며, 각 모델의 예측한 결과들을 모아 다수결 투표로 최종 예측 결과를 선정하는 방식이다.
방금 위에서 표현한 예가 hard voting이다.

Soft Voting
- Probability Voting이라고도 하며, 각 모델들이 예측한 결과값이 아닌! 결과값의 확률을 합산해 최종 예측 결과를 선정하다. 단순히 예측 결과만 고려하지 않고 높은 확률을 반환하는 모델의 비중이 들어가기에 Hard voting보다 성능이 좋다.

이제 코드를 살펴보자.
Voting Classifier에 들어가는 모델은 RandomForest, XGB, LGBM으로 soft voting으로 진행한다.
접은 글은 데이터를 가져오고 전처리하는 과정이다.
# 데이터 다운로드 링크로 데이터를 코랩에 불러옵니다.
!wget 'https://bit.ly/3i4n1QB'
import zipfile
with zipfile.ZipFile('3i4n1QB', 'r') as existing_zip:
existing_zip.extractall('data')
# 라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
train.drop('index',axis = 1 ,inplace =True)
test.drop('index',axis = 1 ,inplace =True)
train.head()
type이란 컬럼이 명목변수이기에 원핫인코딩으로 모델이 학습할 수 있게 바꿔준다.
# 원핫 인코딩 (pd.get_dummies())
train_one=pd.get_dummies(train)
test_one=pd.get_dummies(test)
train_one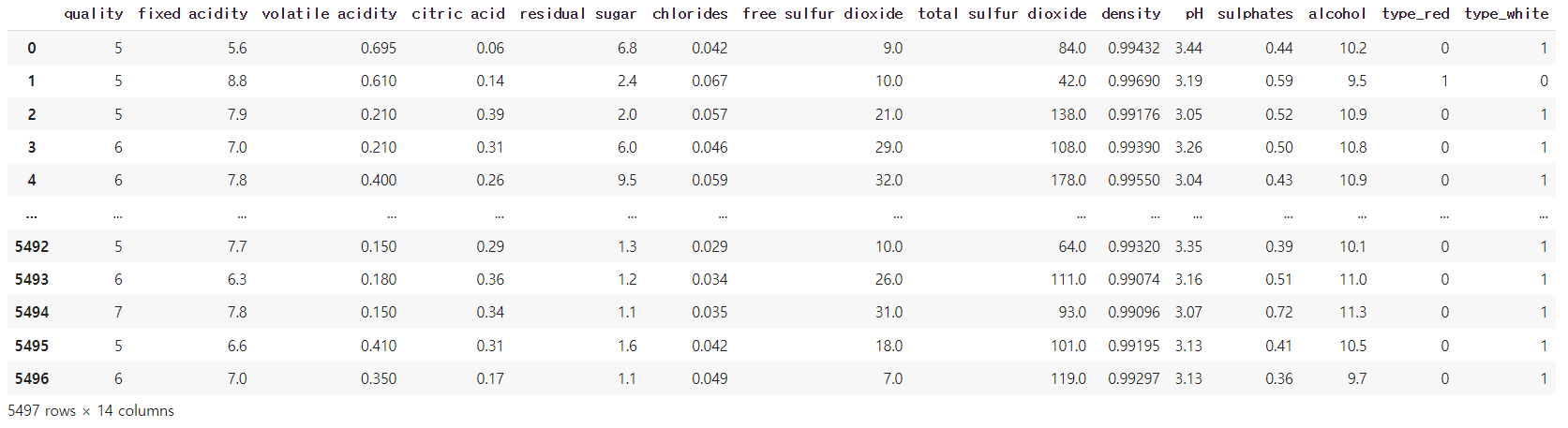
# 모델 정의
from sklearn.ensemble import VotingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
# VotingClassifier 정의
LGBM=LGBMClassifier()
XGB=XGBClassifier()
RF=RandomForestClassifier()
VC=VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting='soft')
# 모델 학습
# X 는 train에서 quality 를 제외한 모든 변수
X=train_one.drop(columns=['quality'],axis=1)
# y 는 train의 qulity 변수
y=train_one['quality']
# fit 메소드를 이용해 모델 학습
VC.fit(X,y)
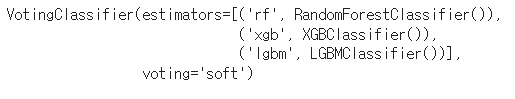
# predict 메소드와 test_one 데이터를 이용해 품질 예측
pred=VC.predict(test_one)
Voting Classifier 하이퍼 파라미터 튜닝
- 다른 모델들과 다르게 voting은 여러 모델들의 결과(결과값 또는 확률값)을 합쳐놓은 모델이다. 그렇기 때문에 모델을 튜닝할때도 여러 모델들을 튜닝시킨 후 넣으면 된다.
pip install bayesian-optimization
# Bayesian Optimization 불러오기
from bayes_opt import BayesianOptimization
RandomForest 튜닝
# X에 학습할 데이터를, y에 목표 변수를 저장해주세요
X = train.drop(columns = ['index', 'quality'])
y = train['quality']
# 랜덤포레스트의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요
## Key는 랜덤포레스트의 hyperparameter이름이고, value는 탐색할 범위 입니다.
rf_params={
'max_depth':(1,3),
'n_estimators':(30,100),
}
# 함수를 만들어주겠습니다.
# 함수의 구성은 다음과 같습니다.
# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들
# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성
# 3. 그 딕셔너리를 바탕으로 모델 생성
# 4. train_test_split을 통해 데이터 train-valid 나누기
# 5 .모델 학습
# 6. 모델 성능 측정
# 7. 모델의 점수 반환
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold,train_test_split
from sklearn.metrics import accuracy_score
def rf_bo(max_depth, n_estimators):
params={
'max_depth':int(round(max_depth)),
'n_estimators':int(round(n_estimators)),
}
model=RandomForestClassifier(**params)
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.8)
model.fit(X_train, y_train)
score=accuracy_score(y_valid, model.predict(X_valid))
return score
# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다.
# "BO_rf"라는 변수에 Bayesian Optmization을 저장해보세요
BO_rf = BayesianOptimization(f=rf_bo,pbounds=rf_params,random_state=3,verbose=2)
# Bayesian Optimization을 실행해보세요
BO_rf.maximize(init_points=5, n_iter=5)
rf_max_params=BO_rf.max['params']
rf_max_params['max_depth']=int(rf_max_params['max_depth'])
rf_max_params['n_estimators']=int(rf_max_params['n_estimators'])
rf_max_params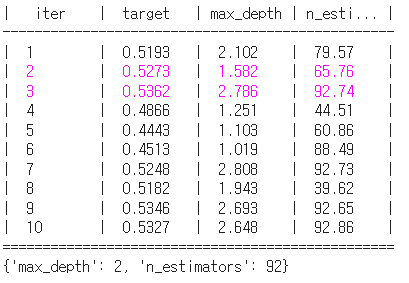
XGB 튜닝
# XGBoost의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요
X = train.drop(columns = ['index', 'quality'])
y = train['quality']
## Key는 XGBoost hyperparameter이름이고, value는 탐색할 범위 입니다.
xgb_params={
'gamma':(0,10),
'max_depth':(1,3),
'subsample':(0.5,1),
}
# 함수를 만들어주겠습니다.
# 함수의 구성은 다음과 같습니다.
# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들
# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성
# 3. 그 딕셔너리를 바탕으로 모델 생성
# 4. train_test_split을 통해 데이터 train-valid 나누기
# 5 .모델 학습
# 6. 모델 성능 측정
# 7. 모델의 점수 반환
from xgboost import XGBClassifier
def xgb_bo(gamma,max_depth, subsample):
params={
'gamma':int(round(gamma)),
'max_depth':int(round(max_depth)),
'subsample':int(round(subsample)),
}
model=XGBClassifier(**params)
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.2)
model.fit(X_train,y_train)
score=accuracy_score(y_valid,model.predict(X_valid))
return score
# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다.
# "BO_xgb"라는 변수에 Bayesian Optmization을 저장해보세요
BO_xgb = BayesianOptimization(f=xgb_bo,pbounds=xgb_params,random_state=3,verbose=2)
# Bayesian Optimization을 실행해보세요
BO_xgb.maximize(init_points=5,n_iter=5)
xgb_max_params=BO_xgb.max['params']
xgb_max_params['max_depth']=int(xgb_max_params['max_depth'])
xgb_max_params
LGBM 튜닝
# X에 학습할 데이터를, y에 목표 변수를 저장해주세요
X = train.drop(columns = ['index', 'quality'])
y = train['quality']
# LGBM의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요
## Key는 LGBM hyperparameter이름이고, value는 탐색할 범위 입니다.
lgbm_params={
'n_estimators':(30,100),
'max_depth':(1,3),
'subsample':(0.5,1)
}
# 함수를 만들어주겠습니다.
# 함수의 구성은 다음과 같습니다.
# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들
# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성
# 3. 그 딕셔너리를 바탕으로 모델 생성
# 4. train_test_split을 통해 데이터 train-valid 나누기
# 5. 모델 학습
# 6. 모델 성능 측정
# 7. 모델의 점수 반환
from lightgbm import LGBMClassifier
def lgbm_bo(n_estimators,max_depth, subsample):
params={
'n_estimaotrs':int(round(n_estimators)),
'max_depth':int(round(max_depth)),
'subsample':int(round(subsample)),
}
model=LGBMClassifier(**params)
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.2)
model.fit(X_train,y_train)
score=accuracy_score(y_valid,model.predict(X_valid))
return score
# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다.
# "BO_lgbm"라는 변수에 Bayesian Optmization을 저장해보세요
BO_lgbm = BayesianOptimization(f=lgbm_bo,pbounds=lgbm_params,random_state=3,verbose=2)
# Bayesian Optimization을 실행해보세요
BO_lgbm.maximize(init_points=5,n_iter=5)
lgbm_max_params=BO_lgbm.max['params']
lgbm_max_params['n_estimators']=int(lgbm_max_params['n_estimators'])
lgbm_max_params['max_depth']=int(lgbm_max_params['max_depth'])
lgbm_max_params
Voting Classifier 생성
# 모델 정의 (튜닝된 파라미터로)
LGBM = LGBMClassifier(**lgbm_max_params)
XGB = XGBClassifier(**xgb_max_params)
RF = RandomForestClassifier(**rf_max_params)
from sklearn.ensemble import VotingClassifier
# VotingClassifier 정의
VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting='soft')
fit의 출력물을 보면 우리가 찾아줬던 각 모델의 하이퍼 파라미터들이 들어간 것을 볼 수 있다.
VC.fit(X,y)
test=test.drop(columns='index',axis=1)
pred=VC.predict(test)
sub=pd.read_csv('data/sample_submission.csv')
sub['quality']=pred
sub.to_csv('tuned_voting.csv',index=False)'ML > ML-Kaggle, 데이콘' 카테고리의 다른 글
| LGBM(Light Gradient Boosting Model) (0) | 2021.12.30 |
|---|---|
| XGB(Extreme Gradient Boosting) (0) | 2021.12.30 |
| 차원 축소 (0) | 2021.12.29 |
| 다중공산성 해결 방법 (0) | 2021.12.29 |
| 다중공산성 (0) | 2021.12.17 |



댓글