LGBM을 알기전에 XGB, GBM을 알아야 한다. https://lucian-blog.tistory.com/100
LGBM은 XGB의 업그레이드 버전이라 보면 된다.
XGB는 높은 성능을 내고 GBM보다 빠르지만 여전히 level-wise 트리 확장 구조를 사용하므로 느리다!
즉 트리 구조가 수평적으로 예쁘게 확장되는 것이 level-wise 확장 구조이다.
반면에 LGBM(Light GBM)은 leaf-wise 트리 확장 구조로 변경하여 속도와 메모리를 비약적으로 향상시켰다.
즉 트리의 어느 레벨에서 모든 노드를 확장시키는 것이 아닌 최종 노드 하나만 분할하는 방식을 사용한 것이다.
=수직 트리 구조
이렇게 하면 loss가 가장 큰 부분을 쪼개고 쪼개서 결국 최대한으로 줄여지는 것이 가능하다.
이렇게 하면 level-wise보다 loss를 크게 줄일 수 있다고 한다.
또한 다른 노드들을 분할시키기 않고 오로지 residual이 큰 노드만 쪼개다보니 데이터의 절약과 속도를 향상시킬 수 있다.

LGBM의 장점
- 대용량 데이터를 사용할 수 있다.
- 효율적으로 메모리를 사용한다. (노드의 갯수가 적으니깐!)
- 빠르다!
- + GPU까지 지원해준다.
LGBM의 단점
- 과적합(overfitting)에 민감하다. -loss를 줄이는 것에 집중하다보니 과적합에 민감하여 작은데이터에 쓰는 것은 추천하지 않는다고 한다. 보통 1만개 이상의 행을 가진 데이터에 사용하는 것을 추천한다.
이제 코드로 넘어가자.
LGBM을 사용하여 모델을 만들어보자. (+ Stratified K-fold를 사용해 검증데이터로 성능도 체크해본다.)
Stratified K-fold는 https://lucian-blog.tistory.com/90?category=1002577 이 포스트를 보자.
접은 글은 데이터를 가져와서 가공하는 가정이다.
# 데이터 다운로드 링크로 데이터를 코랩에 불러옵니다.
!wget 'https://bit.ly/3i4n1QB'
import zipfile
with zipfile.ZipFile('3i4n1QB', 'r') as existing_zip:
existing_zip.extractall('data')
# 라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
train.drop('index',axis = 1 ,inplace =True)
test.drop('index',axis = 1 ,inplace =True)
train.head()
type이란 컬럼이 명목변수이기에 원핫인코딩으로 모델이 학습할 수 있게 바꿔준다.
# 원핫 인코딩 (pd.get_dummies())
train_one=pd.get_dummies(train)
test_one=pd.get_dummies(test)
train_one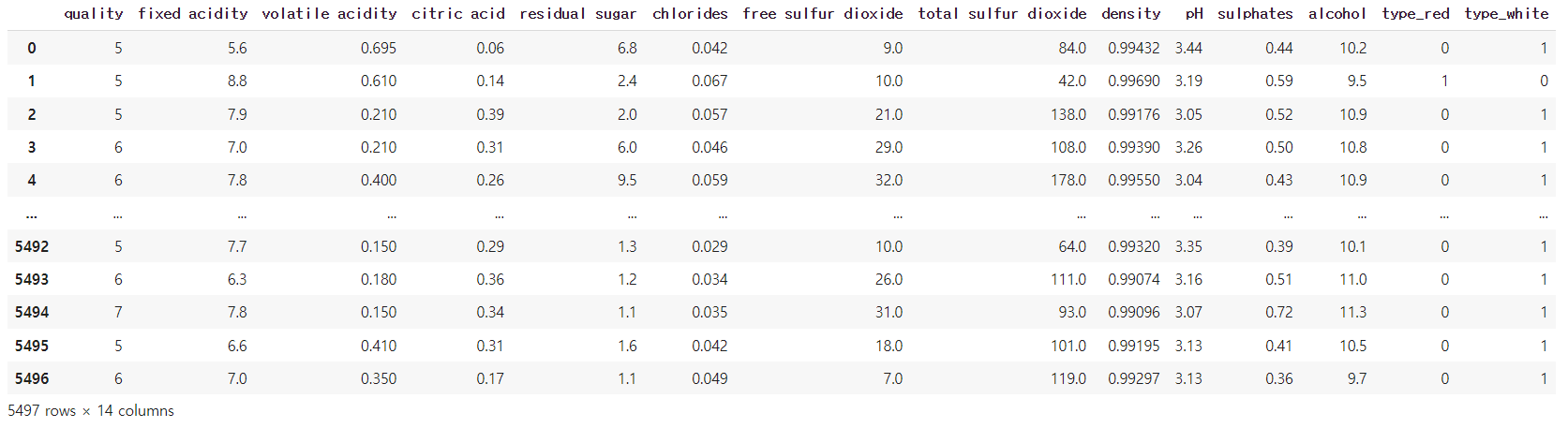
# StratifiedKFold라이브러리를 이용해 5개의 fold로 나눔.
from sklearn.model_selection import StratifiedKFold
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
stratifiedkfold=StratifiedKFold(n_splits=5)
X=train_one.drop(columns=['quality'],axis=1)
y=train_one['quality']
acc = 0
for train_idx, valid_idx in stratifiedkfold.split(X,y):
train_data=train_one.iloc[train_idx]
valid_data=train_one.iloc[valid_idx]
train_X=train_data.drop(columns=['quality'],axis=1)
train_y=train_data['quality']
valid_X=valid_data.drop(columns=['quality'],axis=1)
valid_y=valid_data['quality']
lgbm_model=LGBMClassifier()
lgbm_model.fit(train_X,train_y)
pred=lgbm_model.predict(valid_X)
score=accuracy_score(pred, valid_y)
print('valid 점수 : ',score)
acc +=score
print('total score : ',acc/5)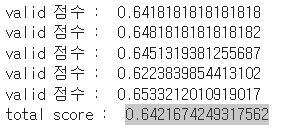
LGBM 하이퍼 파라미터 튜닝
pip install bayesian-optimization
# Bayesian Optimization 불러오기
from bayes_opt import BayesianOptimization
# LGBM의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요
## Key는 LGBM hyperparameter이름이고, value는 탐색할 범위 입니다.
lgbm_params={
'n_estimators':(30,100),
'max_depth':(1,3),
'subsample':(0.5,1)
}
# 함수를 만들어주겠습니다.
# 함수의 구성은 다음과 같습니다.
# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들
# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성
# 3. 그 딕셔너리를 바탕으로 모델 생성
# 4. train_test_split을 통해 데이터 train-valid 나누기
# 5. 모델 학습
# 6. 모델 성능 측정
# 7. 모델의 점수 반환
from lightgbm import LGBMClassifier
from sklearn.model_selection import KFold,train_test_split
from sklearn.metrics import accuracy_score
def lgbm_bo(n_estimators, max_depth, subsample):
params={
'n_estimators':int(round(n_estimators)),
'max_depth':int(round(max_depth)),
'subsample':int(round(subsample)),
}
lgbm_model=LGBMClassifier(**params)
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.2)
lgbm_model.fit(X_train,y_train)
score=accuracy_score(y_valid,lgbm_model.predict(X_valid))
return score
# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다.
# "BO_lgbm"라는 변수에 Bayesian Optmization을 저장해보세요
BO_lgbm=BayesianOptimization(f=lgbm_bo,pbounds=lgbm_params,random_state=0,verbose=2)
BO_lgbm.maximize(init_points=5,n_iter=5)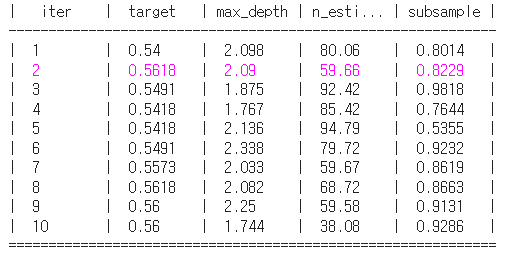
max_params=BO_lgbm.max['params']
max_params['max_depth']=int(max_params['max_depth'])
max_params['n_estimators']=int(max_params['n_estimators'])
max_params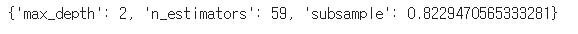
최적의 하이퍼 파라미터를 찾아냈다. 이제 모델에 넣어보자.
# predict 메소드와 test 데이터를 이용해 품질 예측
lgbm_tuned=LGBMClassifier(**max_params)
lgbm_tuned.fit(X,y)
pred=lgbm_tuned.predict(test_one)
제출~
sub=pd.read_csv('data/sample_submission.csv')
sub['quality']=pred
sub.to_csv('lgbm_tuned.csv',index=False)'ML > ML-Kaggle, 데이콘' 카테고리의 다른 글
| Voting Classifier (0) | 2021.12.30 |
|---|---|
| XGB(Extreme Gradient Boosting) (0) | 2021.12.30 |
| 차원 축소 (0) | 2021.12.29 |
| 다중공산성 해결 방법 (0) | 2021.12.29 |
| 다중공산성 (0) | 2021.12.17 |



댓글