GBM은 Gradient Boosting Model로 머신러닝 앙상블 기법 중 하나인 부스팅에서 나온 것이다.
다른 배깅과 랜덤포레스트 같은 경우, 모든 데이터가 순차적이지 않고 병렬적으로 뽑아서 예측하는 것에 반해
부스팅은 순차적으로 모델이 데이터에서 학습한 결과를 가지고 다른 모델이 input으로 쓴다. 즉 모델의 output을 다른 모델이 input으로 받아 진행하는 앙상블 기법이다.
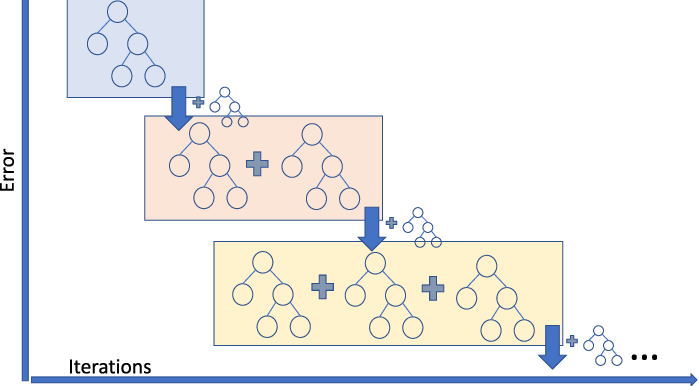
보통 회귀문제에선 loss function은 MSE로 사용한다. MSE로 나온 잔차(residual)를 이용해서 다음 모델을 순차적으로 만들어 나간다는 뜻이다. 즉 negative gradient를 이용해서 다음 모델을 만든다는 것을 의미한다. 그렇기 때문에 gradient로 부스팅을 해서 Gradient Boosting이란 이름이 되었고 loss function의 loss가 줄어드는 방향으로 업데이트 된다는 의미이다.
뭐랄까... 경사하강법과 같다.
이 GBM은 ML 계열의 모델 중 성능이 높은편에 속하고 대신 느리다.
왜냐면 딥러닝의 학습방법의 일부를 썼으므로! 아닌가 딥러닝이 이걸 베낀건가
'ML > ML-Kaggle, 데이콘' 카테고리의 다른 글
| Bayesian Optimization (2) | 2021.12.16 |
|---|---|
| Hold-out, 교차검증(K-Flod), Stratified K-fold (0) | 2021.12.09 |
| EDA (0) | 2021.10.08 |
| OneHot 인코딩-OneHotEncoder(), pd.get_dummies() (4) | 2021.10.08 |
| 수치형 데이터 정규화 (0) | 2021.10.08 |




댓글